
The objective of this study is to classify various types of sports on the basis of snapshots or images of those respective sports.
This model can be used to classify sports images or snapshots as per their respective categories.
Implementation is here…
About the dataset
This dataset was developed by Gerry [Retiired Director Satcom at General Dynamics · Scottsdale, Arizona, United States] with the objective of building a clean dataset that would be easy to use and should not be containing bad or duplicate images between train, test, and validation datasets.
According to Gerry, for the preparation of this dataset, images were gathered from internet searches. The images were scanned with a duplicate image detector program written by himself and any duplicate images were removed to prevent bleed through of images between the train, test, and valid data sets.
All images were then resized to 224 X224 X 3 and converted to jpg format. Additionally, a csv file is included that for each image file contains the relative path to the image file, the image file class label and the dataset (train, test or valid) that the image file resides in.
This is a clean dataset. If you build a good model you should achieve at least 95% accuracy on the test set. If you build a very good model for example using transfer learning you should be able to achieve 98%+ on test set accuracy.
Content
This dataset includes collection of sports images covering 73 different sports.. Images are stored in 224,224,3 jpg format. Further, data is separated into train, test and valid directories and additionally a csv file is included for those that wish to use it to create there own train, test and validation datasets.
Original Dataset Size was 350 MB. However, I reduced the image size parameters of this dataset, hence, the size of dataset used here is 83 MB.
Data Preparation
In this dataset, we were provided 2directories with 73 different directories each consisting of approximately 120 images.
After creating the test set, we can validate whether both the directories, namely “train” and “test” have the same number of classes.
Image Preprocessing
As per the technical definition, Image processing is the technical analysis of an image by using complex algorithms. Here, we use the image as the input, and the output is returned as useful information about it.
Reviewing training samples:

Below I have discussed the parameters and functions that were defined during image preprocessing:
- target_size(height, width) as (120, 120). In this dataset, we had nearly 120 images for every class. Moreover, all images were types of random snapshots taken from various sports events. i.e, Football, Volleyball, Cricket, etc. Hence, a good resolution size is necessary, since, with poor quality image, our model would not be able to distinguish between football and volleball.
- batch_size(), it is a hyperparameter that simply defines the number of samples to work through before updating the internal model parameters.
- class_mode(), here I used class _mode as “categorical”. Since, it determines the type of label arrays that are returned, here in the case of “categorial”, it will be 2D one-hot encoded labels.
- rotation_range, allow us to randomly rotate images through any degree between 0 and 360 by providing an integer value in its argument.
- zoom_range, takes a float value for zooming in the zoom_range.
- width_shift_range, is a floating point number between 0.0 and 1.0 which specifies the upper bound of the fraction of the total width by which the image is to be randomly shifted, either towards the left or right.
- fill_mode, One of {“constant”, “nearest”, “reflect” or “wrap”}. Default is ‘nearest’.
Defining the model
For this image classification model, we defined a convolutional neural network model with seven layers. Here, 2 layers have ReLU(Rectified Linear Unit), one flatten layer and the last one as dense layer which has a “Softmax” activation function.
Here we used “softmax”, the softmax function is used as the activation function in the output layer of neural network models that predict a multinomial probability distribution. That is, as in this case, we had multiple classes of images.
Moreover, the softmax is very useful as it converts the scores to a normalized probability distribution, which can be later displayed to a user or can be used as input to other systems.
Further, the model was compiled using the categorical cross-entropy loss function.
“Adam” is used as an optimizer, because of its ability to adjust the learning rate of the model on its own as per the situation.
Callbacks
Here we used multiple callbacks, a callback is simply an object that can perform actions at various stages of training(e.g. at the start or end of an epoch, before or after a single batch, etc).
- Early Stopping: It is used to stop training when a monitored metric has stopped improving.
- Reduce LR On Plateau: It is used to reduce learning rate when a metric has stopped improving.
- Model Checkpoint: It is used to save the Keras model or model weights at some frequency.
Model Summary
Using fit()
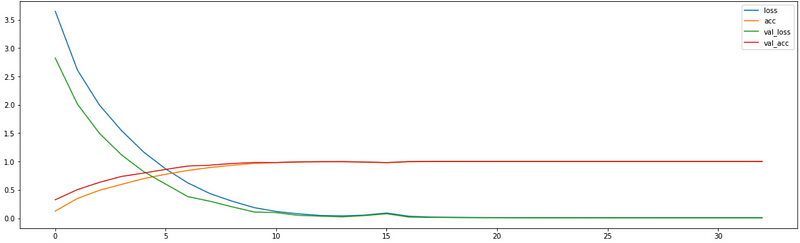
The model achieved an exceptional accuracy of 99% on the validation set and 99% of accuracy on the test set.
Plotting Graphs
The graph between loss, accuracy, validation loss, and validation accuracy.
- “loss” represented training loss
- “acc” represented training accuracy
- “val_loss” represented validation accuracy
- “val_acc” represented validation accuracy
Evaluating the model
Notebook Link: https://cainvas.ai-tech.systems/use-cases/sports-classification-app/
Credit: Akash Rawat
Also Read: Windmill Fault Prediction App