
Resume Screening is necessary when companies receive thousands of applications for different roles and need to find suitable matches.
For this project, the dataset originally consists of 2 columns — Category and Resume, where the Category denotes the field (eg: Data Science, HR, Testing etc.). By using the resume as an input, we need to classify it into one of the categories
Content –
- Analysing the Dataset
- Pre-processing
- Tokenize features and label
- Training model
- Evaluation
Analysis of the Dataset –
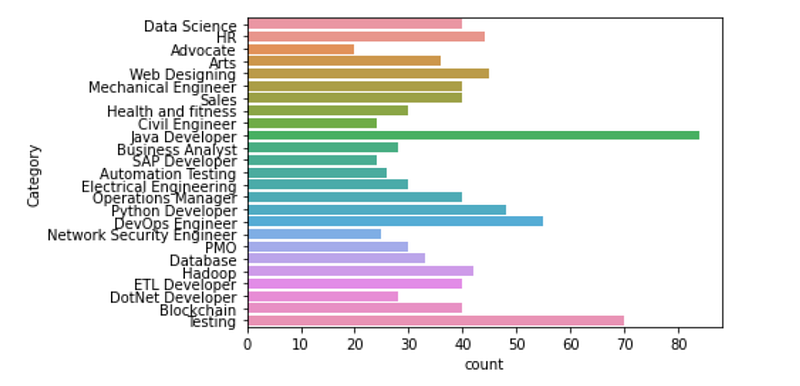
By using value_counts on Category, we can find the frequency-wise distribution of different categories present in our dataset.
resume[\'Category\'].value_counts()
We can visualize the most common set of words in all of the resumes from our dataset by using nltk and wordcloud.
The following wordcloud is obtained –

Pre-processing the Resumes –
During pre-processing, we need to remove links, hashtags, urls etc. as these are irrelevant in the resume. Further, using nltk, we also remove stopwords (for eg words like ‘are’, ‘the’, ‘or’) that provide no significance to the content.
Tokenizing Features and Labels –
After cleaning, pre-processing and splitting the data into train:test, we need to tokenize features and labels such that the most frequent words are given less weightage and the less frequent words are given more significance.
This makes the redundant words less important and the unique words are made more useful.
- Tokenizing features –
- Tokenizing labels –
Training a Sequential Model –

Evaluating our model –
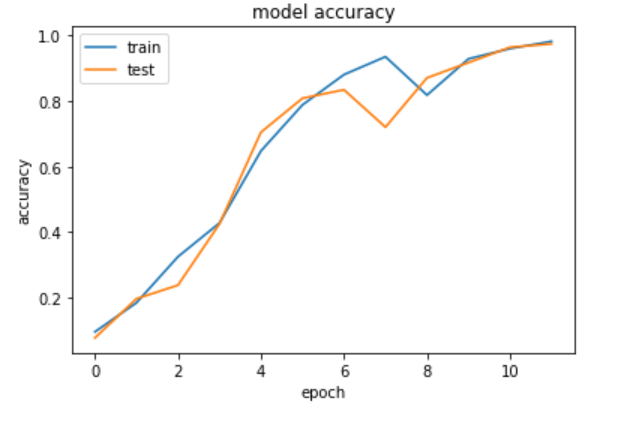
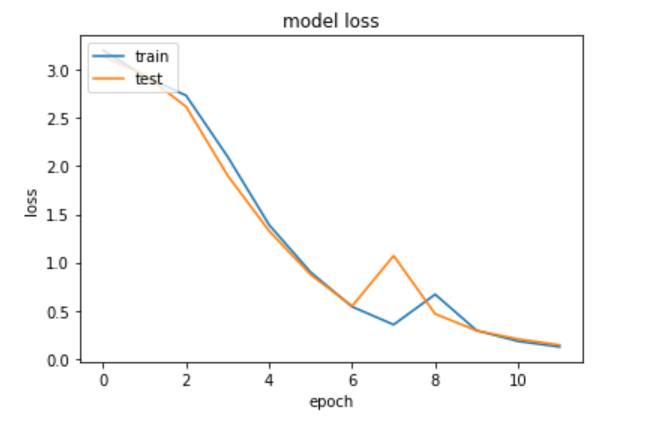
By using evaluate, we have received a test score of around 14% and an accuracy of around 90%.
The accuracy and loss curves over epochs are as follows —
Graphs-
Let’s make some predictions using our model!
Here I have chosen any 3 random input resume from our test set.
We get the output as:
array([ 7, 17, 14])
The output is the tokenized form of our categories, where the tokens are as follows:

Hence, our output can be read as : 7- hadoop, 17- pmo and 14- arts
To verify the predictions, we can print the corresponding test labels —
We get the following output –
hadoop pmo arts
Hence, our custom predictions were correct.
Link to notebook — https://cainvas.ai-tech.systems/use-cases/resume-screening-app/
Credit: Amruta Koshe