Key Facial Points Detection has many applications in the field of IOT and is widely used in many Face Applications related task such as Face Recognition, Drowsiness Detection, and many more. Face Recognition is used for security verification and has many other applications as well.
Table of Content
- Introduction to cAInvas
- Importing the Dataset
- Data Analysis
- Data Augmentation
- Model Training
- Introduction to DeepC
- Compilation with DeepC
- Face Recognition
Introduction to cAInvas
cAInvas is an integrated development platform to create intelligent edge devices. Not only we can train our deep learning model using Tensorflow, Keras, or Pytorch, we can also compile our model with its edge compiler called DeepC to deploy our working model on edge devices for production.
The Key Facial Points Detection model is also a part of cAInvas gallery. All the dependencies which you will be needing for this project are also pre-installed.
cAInvas also offers various other deep learning notebooks in its gallery which one can use for reference or to gain insight about deep learning. It also has GPU support and which makes it the best in its kind.
Importing the Dataset
While working on cAInvas one of its key features is UseCases Gallary. When working on any of its UseCases you don’t have to look for data manually. As they have the feature to import the dataset to your workspace when you work on them.
To load the data we will use pandas library and load the csv dataset which includes co-ordinates of Key Facial Points and the last column contains pixel values of the image. We just have to run the following commands:
Data Analysis
In this step, we will analyze our data. Our csv data consists of 31 columns. The first 30 columns consists the co-ordinates of the fifteen key facial features and the last column contains the pixel values of the image of people.
Since pixel values for the image is given as space separated string, we will convert this into numpy array and convert the obtained 1D array into 2D array of shape (96,96). The plotted image along with key facial points looks like this:
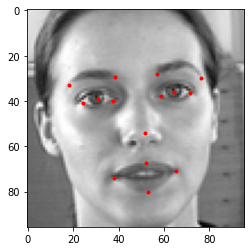
Data Augmentation
For data augmentation, we will flip the images along x-axis and increase or decrease the brightness of the image. Since we are flipping the images horizontally, y coordinate values would be the same.
X-coordinate values only would be changed, all we have to do is to subtract our initial x-coordinate values from width of the image(96). The original image, flipped image and increased brightness image looks like this:
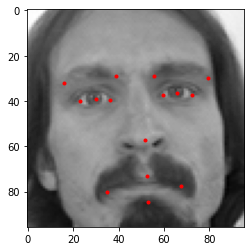
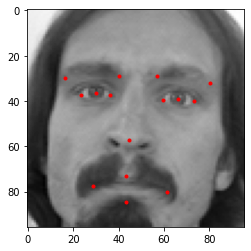

Next we will pass the pixel values of the images as input to our model and we will train our deep learning model to predict the co-ordinates of the fifteen key facial points.
Model Training
After creating the trainset and testset, next step is to pass our training data into our Deep Learning model to learn to predict the co-ordinates of the key facial points. The model architecture used was:
Model: "functional_1" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 96, 96, 1)] 0 __________________________________________________________________________________________________ zero_padding2d (ZeroPadding2D) (None, 102, 102, 1) 0 input_1[0][0] __________________________________________________________________________________________________ conv1 (Conv2D) (None, 48, 48, 64) 3200 zero_padding2d[0][0] __________________________________________________________________________________________________ bn_conv1 (BatchNormalization) (None, 48, 48, 64) 256 conv1[0][0] __________________________________________________________________________________________________ activation (Activation) (None, 48, 48, 64) 0 bn_conv1[0][0] __________________________________________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 23, 23, 64) 0 activation[0][0] __________________________________________________________________________________________________ res_2_conv_a (Conv2D) (None, 23, 23, 64) 4160 max_pooling2d[0][0] __________________________________________________________________________________________________ max_pooling2d_1 (MaxPooling2D) (None, 11, 11, 64) 0 res_2_conv_a[0][0] __________________________________________________________________________________________________ bn_2_conv_a (BatchNormalization (None, 11, 11, 64) 256 max_pooling2d_1[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 11, 11, 64) 0 bn_2_conv_a[0][0] __________________________________________________________________________________________________ res_2_conv_b (Conv2D) (None, 11, 11, 64) 36928 activation_1[0][0] __________________________________________________________________________________________________ bn_2_conv_b (BatchNormalization (None, 11, 11, 64) 256 res_2_conv_b[0][0] __________________________________________________________________________________________________ activation_2 (Activation) (None, 11, 11, 64) 0 bn_2_conv_b[0][0] __________________________________________________________________________________________________ res_2_conv_copy (Conv2D) (None, 23, 23, 256) 16640 max_pooling2d[0][0] __________________________________________________________________________________________________ res_2_conv_c (Conv2D) (None, 11, 11, 256) 16640 activation_2[0][0] __________________________________________________________________________________________________ max_pooling2d_2 (MaxPooling2D) (None, 11, 11, 256) 0 res_2_conv_copy[0][0] __________________________________________________________________________________________________ bn_2_conv_c (BatchNormalization (None, 11, 11, 256) 1024 res_2_conv_c[0][0] __________________________________________________________________________________________________ bn_2_conv_copy (BatchNormalizat (None, 11, 11, 256) 1024 max_pooling2d_2[0][0] __________________________________________________________________________________________________ add (Add) (None, 11, 11, 256) 0 bn_2_conv_c[0][0] bn_2_conv_copy[0][0] __________________________________________________________________________________________________ activation_3 (Activation) (None, 11, 11, 256) 0 add[0][0] __________________________________________________________________________________________________ res_2_identity_1_a (Conv2D) (None, 11, 11, 64) 16448 activation_3[0][0] __________________________________________________________________________________________________ bn_2_identity_1_a (BatchNormali (None, 11, 11, 64) 256 res_2_identity_1_a[0][0] __________________________________________________________________________________________________ activation_4 (Activation) (None, 11, 11, 64) 0 bn_2_identity_1_a[0][0] __________________________________________________________________________________________________ res_2_identity_1_b (Conv2D) (None, 11, 11, 64) 36928 activation_4[0][0] __________________________________________________________________________________________________ bn_2_identity_1_b (BatchNormali (None, 11, 11, 64) 256 res_2_identity_1_b[0][0] __________________________________________________________________________________________________ activation_5 (Activation) (None, 11, 11, 64) 0 bn_2_identity_1_b[0][0] __________________________________________________________________________________________________ res_2_identity_1_c (Conv2D) (None, 11, 11, 256) 16640 activation_5[0][0] __________________________________________________________________________________________________ bn_2_identity_1_c (BatchNormali (None, 11, 11, 256) 1024 res_2_identity_1_c[0][0] __________________________________________________________________________________________________ add_1 (Add) (None, 11, 11, 256) 0 bn_2_identity_1_c[0][0] activation_3[0][0] __________________________________________________________________________________________________ activation_6 (Activation) (None, 11, 11, 256) 0 add_1[0][0] __________________________________________________________________________________________________ res_2_identity_2_a (Conv2D) (None, 11, 11, 64) 16448 activation_6[0][0] __________________________________________________________________________________________________ bn_2_identity_2_a (BatchNormali (None, 11, 11, 64) 256 res_2_identity_2_a[0][0] __________________________________________________________________________________________________ activation_7 (Activation) (None, 11, 11, 64) 0 bn_2_identity_2_a[0][0] __________________________________________________________________________________________________ res_2_identity_2_b (Conv2D) (None, 11, 11, 64) 36928 activation_7[0][0] __________________________________________________________________________________________________ bn_2_identity_2_b (BatchNormali (None, 11, 11, 64) 256 res_2_identity_2_b[0][0] __________________________________________________________________________________________________ activation_8 (Activation) (None, 11, 11, 64) 0 bn_2_identity_2_b[0][0] __________________________________________________________________________________________________ res_2_identity_2_c (Conv2D) (None, 11, 11, 256) 16640 activation_8[0][0] __________________________________________________________________________________________________ bn_2_identity_2_c (BatchNormali (None, 11, 11, 256) 1024 res_2_identity_2_c[0][0] __________________________________________________________________________________________________ add_2 (Add) (None, 11, 11, 256) 0 bn_2_identity_2_c[0][0] activation_6[0][0] __________________________________________________________________________________________________ activation_9 (Activation) (None, 11, 11, 256) 0 add_2[0][0] __________________________________________________________________________________________________ res_3_conv_a (Conv2D) (None, 11, 11, 128) 32896 activation_9[0][0] __________________________________________________________________________________________________ max_pooling2d_3 (MaxPooling2D) (None, 5, 5, 128) 0 res_3_conv_a[0][0] __________________________________________________________________________________________________ bn_3_conv_a (BatchNormalization (None, 5, 5, 128) 512 max_pooling2d_3[0][0] __________________________________________________________________________________________________ activation_10 (Activation) (None, 5, 5, 128) 0 bn_3_conv_a[0][0] __________________________________________________________________________________________________ res_3_conv_b (Conv2D) (None, 5, 5, 128) 147584 activation_10[0][0] __________________________________________________________________________________________________ bn_3_conv_b (BatchNormalization (None, 5, 5, 128) 512 res_3_conv_b[0][0] __________________________________________________________________________________________________ activation_11 (Activation) (None, 5, 5, 128) 0 bn_3_conv_b[0][0] __________________________________________________________________________________________________ res_3_conv_copy (Conv2D) (None, 11, 11, 512) 131584 activation_9[0][0] __________________________________________________________________________________________________ res_3_conv_c (Conv2D) (None, 5, 5, 512) 66048 activation_11[0][0] __________________________________________________________________________________________________ max_pooling2d_4 (MaxPooling2D) (None, 5, 5, 512) 0 res_3_conv_copy[0][0] __________________________________________________________________________________________________ bn_3_conv_c (BatchNormalization (None, 5, 5, 512) 2048 res_3_conv_c[0][0] __________________________________________________________________________________________________ bn_3_conv_copy (BatchNormalizat (None, 5, 5, 512) 2048 max_pooling2d_4[0][0] __________________________________________________________________________________________________ add_3 (Add) (None, 5, 5, 512) 0 bn_3_conv_c[0][0] bn_3_conv_copy[0][0] __________________________________________________________________________________________________ activation_12 (Activation) (None, 5, 5, 512) 0 add_3[0][0] __________________________________________________________________________________________________ res_3_identity_1_a (Conv2D) (None, 5, 5, 128) 65664 activation_12[0][0] __________________________________________________________________________________________________ bn_3_identity_1_a (BatchNormali (None, 5, 5, 128) 512 res_3_identity_1_a[0][0] __________________________________________________________________________________________________ activation_13 (Activation) (None, 5, 5, 128) 0 bn_3_identity_1_a[0][0] __________________________________________________________________________________________________ res_3_identity_1_b (Conv2D) (None, 5, 5, 128) 147584 activation_13[0][0] __________________________________________________________________________________________________ bn_3_identity_1_b (BatchNormali (None, 5, 5, 128) 512 res_3_identity_1_b[0][0] __________________________________________________________________________________________________ activation_14 (Activation) (None, 5, 5, 128) 0 bn_3_identity_1_b[0][0] __________________________________________________________________________________________________ res_3_identity_1_c (Conv2D) (None, 5, 5, 512) 66048 activation_14[0][0] __________________________________________________________________________________________________ bn_3_identity_1_c (BatchNormali (None, 5, 5, 512) 2048 res_3_identity_1_c[0][0] __________________________________________________________________________________________________ add_4 (Add) (None, 5, 5, 512) 0 bn_3_identity_1_c[0][0] activation_12[0][0] __________________________________________________________________________________________________ activation_15 (Activation) (None, 5, 5, 512) 0 add_4[0][0] __________________________________________________________________________________________________ res_3_identity_2_a (Conv2D) (None, 5, 5, 128) 65664 activation_15[0][0] __________________________________________________________________________________________________ bn_3_identity_2_a (BatchNormali (None, 5, 5, 128) 512 res_3_identity_2_a[0][0] __________________________________________________________________________________________________ activation_16 (Activation) (None, 5, 5, 128) 0 bn_3_identity_2_a[0][0] __________________________________________________________________________________________________ res_3_identity_2_b (Conv2D) (None, 5, 5, 128) 147584 activation_16[0][0] __________________________________________________________________________________________________ bn_3_identity_2_b (BatchNormali (None, 5, 5, 128) 512 res_3_identity_2_b[0][0] __________________________________________________________________________________________________ activation_17 (Activation) (None, 5, 5, 128) 0 bn_3_identity_2_b[0][0] __________________________________________________________________________________________________ res_3_identity_2_c (Conv2D) (None, 5, 5, 512) 66048 activation_17[0][0] __________________________________________________________________________________________________ bn_3_identity_2_c (BatchNormali (None, 5, 5, 512) 2048 res_3_identity_2_c[0][0] __________________________________________________________________________________________________ add_5 (Add) (None, 5, 5, 512) 0 bn_3_identity_2_c[0][0] activation_15[0][0] __________________________________________________________________________________________________ activation_18 (Activation) (None, 5, 5, 512) 0 add_5[0][0] __________________________________________________________________________________________________ Averagea_Pooling (AveragePoolin (None, 2, 2, 512) 0 activation_18[0][0] __________________________________________________________________________________________________ flatten (Flatten) (None, 2048) 0 Averagea_Pooling[0][0] __________________________________________________________________________________________________ dense (Dense) (None, 4096) 8392704 flatten[0][0] __________________________________________________________________________________________________ dropout (Dropout) (None, 4096) 0 dense[0][0] __________________________________________________________________________________________________ dense_1 (Dense) (None, 2048) 8390656 dropout[0][0] __________________________________________________________________________________________________ dropout_1 (Dropout) (None, 2048) 0 dense_1[0][0] __________________________________________________________________________________________________ dense_2 (Dense) (None, 30) 61470 dropout_1[0][0] ================================================================================================== Total params: 18,016,286 Trainable params: 18,007,710 Non-trainable params: 8,576 __________________________________________________________________________________________________
The loss function used was “MSE” and optimizer used was “Adam”. For training the model we used Keras API with tensorflow at backend. Here is the training plot and some of test results:
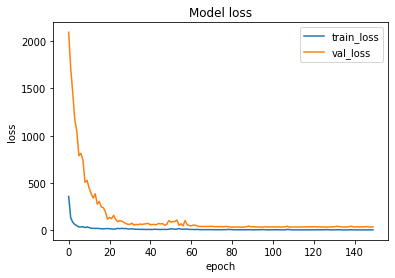

Introduction to DeepC
DeepC Compiler and inference framework is designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, cpus and other embedded devices like raspberry-pi, odroid, arduino, SparkFun Edge, risc-V, mobile phones, x86 and arm laptops among others.
DeepC also offers ahead of time compiler producing optimized executable based on LLVM compiler tool chain specialized for deep neural networks with ONNX as front end.
Compilation with DeepC
After training the model, it was saved in an H5 format using Keras as it easily stores the weights and model configuration in a single file.
After saving the file in H5 format we can easily compile our model using DeepC compiler which comes as a part of cAInvas platform so that it converts our saved model to a format which can be easily deployed to edge devices. And all this can be done very easily using a simple command.
And that’s it, our Key Facial Point Detection Model is trained and ready for deployment on edge devices.
Face Recognition
For the face recognition we are going to use a python library called DLIB. DLIB is a library which contains models which are trained to find KEY FACIAL POINTS using a very large dataset and with a more complex Neural Network Architecture.
It has been trained for a sufficiently long time and it can be used for various Face Applications such as Face Recognition for instance. On how to use DLIB for face recognition you can visit the cAInvas notebook link given at the bottom.
Link for the cAInvas Notebook: https://cainvas.ai-tech.systems/use-cases/face-recognition-app/
Credit: Ashish Arya
Also Read: Detect the weather in images — Image tagging on cAInvas