
MNIST like dataset for Kannada handwritten digits
The goal of this competition is to provide a simple extension to the classic MNIST competition we’re all familiar with. Instead of using Arabic numerals, it uses a recently-released dataset of Kannada digits.
Kannada is a language spoken predominantly by the people of Karnataka in southwestern India. The language has roughly 45 million native speakers and is written using the Kannada script. Wikipedia

This competition uses the same format as the MNIST competition in terms of how the data is structured, but it’s different in that it is a synchronous re-run Kernels competition. You write your code in a Kaggle Notebook, and when you submit the results, your code is scored on both the public test set, as well as a private (unseen) test set.
Technical Information
All details of the dataset curation have been captured in the paper titled: Prabhu, Vinay Uday. “Kannada-MNIST: A new handwritten digits dataset for the Kannada language.” arXiv preprint arXiv:1908.01242 (2019)
The GitHub repo of the author can be found here.
On the originally posted dataset, the author suggests some interesting questions you may be interested in exploring. Please note, although this dataset has been released in full, the purpose of this competition is for practice, not to find the labels to submit a perfect score.
In addition to the main dataset, the author also disseminated an additional real-world handwritten dataset (with 10k images), termed as the ‘Dig-MNIST dataset’ that can serve as an out-of-domain test dataset.
It was created with the help of volunteers that were non-native users of the language, authored on a smaller sheet, and scanned with different scanner settings compared to the main dataset. This ‘dig-MNIST’ dataset serves as a more difficult test-set (An accuracy of 76.1% was reported in the paper cited above) and achieving ~98+% accuracy on this test dataset would be rather commendable.
Importing Libraries
Import Data
Data Preprocessing
Index([\'id\', \'pixel0\', \'pixel1\', \'pixel2\', \'pixel3\', \'pixel4\', \'pixel5\',
\'pixel6\', \'pixel7\', \'pixel8\',
...
\'pixel774\', \'pixel775\', \'pixel776\', \'pixel777\', \'pixel778\', \'pixel779\',
\'pixel780\', \'pixel781\', \'pixel782\', \'pixel783\'],
dtype=\'object\', length=785)
Train Test Split
(48000, 28, 28) (48000,) (12000, 28, 28) (12000,) (5000, 28, 28)
Model Architecture
Model: "functional_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv1 (Conv2D) (None, 28, 28, 16) 160 _________________________________________________________________ batch1 (BatchNormalization) (None, 28, 28, 16) 64 _________________________________________________________________ relu1 (Activation) (None, 28, 28, 16) 0 _________________________________________________________________ dropout (Dropout) (None, 28, 28, 16) 0 _________________________________________________________________ conv2 (Conv2D) (None, 28, 28, 32) 4640 _________________________________________________________________ batch2 (BatchNormalization) (None, 28, 28, 32) 128 _________________________________________________________________ relu2 (Activation) (None, 28, 28, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 28, 28, 32) 0 _________________________________________________________________ max2 (MaxPooling2D) (None, 14, 14, 32) 0 _________________________________________________________________ conv3 (Conv2D) (None, 14, 14, 64) 51264 _________________________________________________________________ batch3 (BatchNormalization) (None, 14, 14, 64) 256 _________________________________________________________________ relu3 (Activation) (None, 14, 14, 64) 0 _________________________________________________________________ max3 (MaxPooling2D) (None, 7, 7, 64) 0 _________________________________________________________________ conv4 (Conv2D) (None, 7, 7, 64) 102464 _________________________________________________________________ batch4 (BatchNormalization) (None, 7, 7, 64) 256 _________________________________________________________________ relu4 (Activation) (None, 7, 7, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 7, 7, 64) 0 _________________________________________________________________ conv5 (Conv2D) (None, 7, 7, 32) 18464 _________________________________________________________________ batch5 (BatchNormalization) (None, 7, 7, 32) 128 _________________________________________________________________ relu5 (Activation) (None, 7, 7, 32) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 7, 7, 32) 0 _________________________________________________________________ conv6 (Conv2D) (None, 7, 7, 16) 4624 _________________________________________________________________ batch6 (BatchNormalization) (None, 7, 7, 16) 64 _________________________________________________________________ relu6 (Activation) (None, 7, 7, 16) 0 _________________________________________________________________ dropout_4 (Dropout) (None, 7, 7, 16) 0 _________________________________________________________________ flatten (Flatten) (None, 784) 0 _________________________________________________________________ Dense1 (Dense) (None, 50) 39250 _________________________________________________________________ relu7 (Activation) (None, 50) 0 _________________________________________________________________ dropout_5 (Dropout) (None, 50) 0 _________________________________________________________________ Dense2 (Dense) (None, 25) 1275 _________________________________________________________________ relu8 (Activation) (None, 25) 0 _________________________________________________________________ dropout_6 (Dropout) (None, 25) 0 _________________________________________________________________ Dense3 (Dense) (None, 10) 260 _________________________________________________________________ activation (Activation) (None, 10) 0 ================================================================= Total params: 223,297 Trainable params: 222,849 Non-trainable params: 448 _________________________________________________________________ None
Training the model
Epoch 1/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0584 - accuracy: 0.9826 - val_loss: 0.0243 - val_accuracy: 0.9942 Epoch 2/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0555 - accuracy: 0.9834 - val_loss: 0.0205 - val_accuracy: 0.9943 Epoch 3/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0554 - accuracy: 0.9832 - val_loss: 0.0218 - val_accuracy: 0.9933 Epoch 4/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0478 - accuracy: 0.9857 - val_loss: 0.0123 - val_accuracy: 0.9965 Epoch 5/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0477 - accuracy: 0.9861 - val_loss: 0.0141 - val_accuracy: 0.9960 Epoch 6/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0463 - accuracy: 0.9862 - val_loss: 0.0111 - val_accuracy: 0.9966 Epoch 7/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0478 - accuracy: 0.9856 - val_loss: 0.0126 - val_accuracy: 0.9961 Epoch 8/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0446 - accuracy: 0.9865 - val_loss: 0.0163 - val_accuracy: 0.9956 Epoch 9/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0412 - accuracy: 0.9874 - val_loss: 0.0121 - val_accuracy: 0.9967 Epoch 10/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0410 - accuracy: 0.9875 - val_loss: 0.0112 - val_accuracy: 0.9968 Epoch 11/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0404 - accuracy: 0.9876 - val_loss: 0.0133 - val_accuracy: 0.9960 Epoch 12/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0386 - accuracy: 0.9881 - val_loss: 0.0113 - val_accuracy: 0.9965 Epoch 13/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0354 - accuracy: 0.9890 - val_loss: 0.0149 - val_accuracy: 0.9955 Epoch 14/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0358 - accuracy: 0.9895 - val_loss: 0.0139 - val_accuracy: 0.9964 Epoch 15/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0331 - accuracy: 0.9894 - val_loss: 0.0125 - val_accuracy: 0.9968 Epoch 16/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0360 - accuracy: 0.9885 - val_loss: 0.0116 - val_accuracy: 0.9966 Epoch 17/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 11s - loss: 0.0352 - accuracy: 0.9900 - val_loss: 0.0144 - val_accuracy: 0.9962 Epoch 18/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0322 - accuracy: 0.9904 - val_loss: 0.0104 - val_accuracy: 0.9973 Epoch 19/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0324 - accuracy: 0.9901 - val_loss: 0.0098 - val_accuracy: 0.9973 Epoch 20/20 WARNING:tensorflow:Can save best model only with val_acc available, skipping. 1500/1500 - 10s - loss: 0.0330 - accuracy: 0.9901 - val_loss: 0.0108 - val_accuracy: 0.9967
Accuracy Loss Graphs
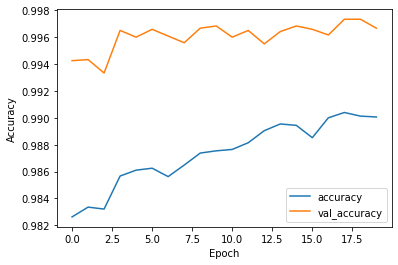
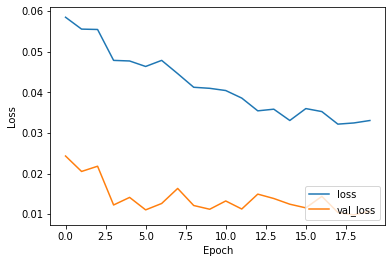
Result and Prediction
array([3, 0, 2, ..., 1, 6, 3])
DeepCC
[INFO] Reading [keras model] \'model.h5\' [SUCCESS] Saved \'model_deepC/model.onnx\' [INFO] Reading [onnx model] \'model_deepC/model.onnx\' [INFO] Model info: ir_vesion : 5 doc : [WARNING] [ONNX]: graph-node conv1\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: graph-node conv2\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: graph-node conv3\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: graph-node conv4\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: graph-node conv5\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: graph-node conv6\'s attribute auto_pad has no meaningful data. [WARNING] [ONNX]: terminal (input/output) input_1\'s shape is less than 1. Changing it to 1. [WARNING] [ONNX]: terminal (input/output) activation\'s shape is less than 1. Changing it to 1. [INFO] Running DNNC graph sanity check ... [SUCCESS] Passed sanity check. [INFO] Writing C++ file \'model_deepC/model.cpp\' [INFO] deepSea model files are ready in \'model_deepC/\' [RUNNING COMMAND] g++ -std=c++11 -O3 -fno-rtti -fno-exceptions -I. -I/opt/tljh/user/lib/python3.7/site-packages/deepC-0.13-py3.7-linux-x86_64.egg/deepC/include -isystem /opt/tljh/user/lib/python3.7/site-packages/deepC-0.13-py3.7-linux-x86_64.egg/deepC/packages/eigen-eigen-323c052e1731 "model_deepC/model.cpp" -D_AITS_MAIN -o "model_deepC/model.exe" [RUNNING COMMAND] size "model_deepC/model.exe" text data bss dec hex filename 1075765 3784 760 1080309 107bf5 model_deepC/model.exe [SUCCESS] Saved model as executable "model_deepC/model.exe"
Notebook Link- Here
Credits: Siddharth Ganjoo
Also Read: Lower Back Pain Symptoms Detection using NN