Classifying Indian currency notes using their images and deep learning.

Currency notes have identifiers that allow the visually impaired to identify them easily. This is a learned skill.
On the other hand, classifying them using images is an easier solution to help the visually impaired identify the currency they are dealing with.
Here, we use pictures of different versions of the currency notes taken from different angles, with different backgrounds and covering different proportions.
Implementation of the idea on cAInvas — here!
The dataset
On Kaggle by Gaurav Rajesh Sahani
The dataset contains 195 images of 7 categories of Indian Currency Notes — Tennote, Fiftynote, Twentynote, 2Thousandnote, 2Hundrednote, Hundrednote, 1Hundrednote.
There are 2 folders in the dataset — train and test, each with 7 sub-folders corresponding to the currency categories.
A peek into the number of images in the folders –
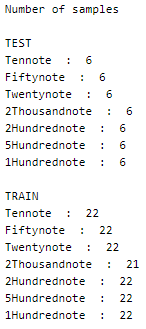
This is a balanced dataset.
The dataset is loaded using the image_dataset_from_directory function of the keras.preprocessing module by specifying the path to the train and test folders. The function parameter specifies that the labels are to be loaded in the categorical mode (one-hot encoded, thus we will be using CategoricalCrossentropy loss in our model later).
The training set has 153 images and the test dataset has 42 images in total.
The class labels are stored in a list format for mapping later.
Visualization
Let us look at examples from the dataset we are dealing with —



Preprocessing
Normalization
The pixel values of these images are integers in the range 0–255. Normalizing the pixel values reduces them to float values in the range [0, 1]. This is done using the Rescaling function of the keras.layers.experimental.preprocessing module.
This helps in faster convergence of the model’s loss function.
The model
Transfer learning is the application of a pre-trained model structure (and weight, optional) to solve the problem at hand. The model may be trained on datasets different from the current problem but the knowledge gained has proven to be effective in solving problems in domains different from the ones that were used for training.
Here, we will be using the DenseNet121 model after removing its last layer (the classification layer) and attaching our own as necessary for the current problem.
The model’s weights will be kept intact while the layers we appended at the end will be trained.
The model uses the categorical cross-entropy loss of the keras.losses module as it is a classification problem with one-hot encoded class labels (loading the dataset using the label_mode as categorical above). Adam optimizer of the keras.optimizers module was used and the model’s accuracy metric was tracked to review the model’s performance.
The EarlyStopping callback function of the keras.callbacks module is used to monitor the metrics (default, val_loss) and stop the training if the metric doesn’t improve (increase or decrease based on metric specified) continuously for 5 epochs (patience parameter).
The restore_best_weights parameter is set to true to ensure that the model is loaded with weights corresponding to the checkpoint with the best metric value at the end of the training process.
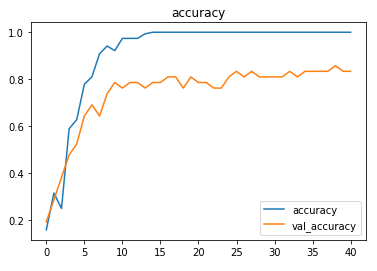
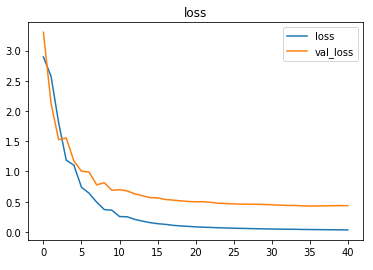
The model is trained with a learning rate of 0.01 and achieves ~83% accuracy on the test set.
Better images or augmentation techniques can help improve the model’s performance.

The confusion matrix is as follows —
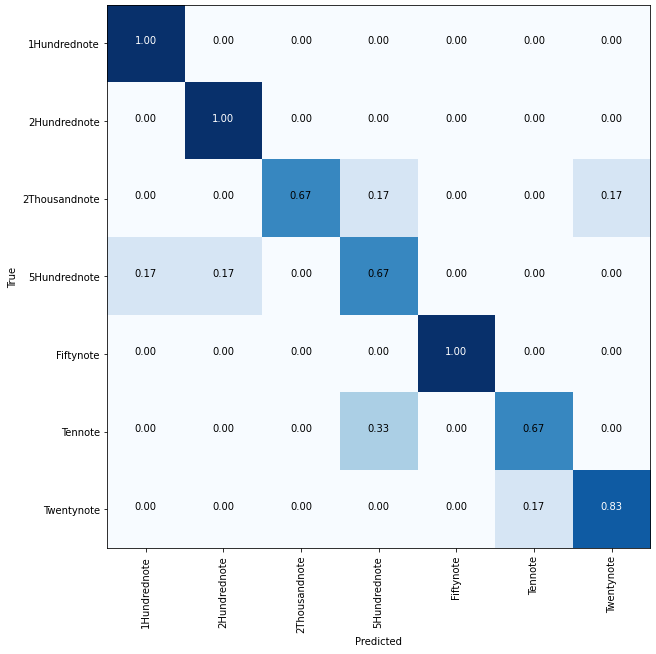
The metrics
Prediction
Let us look at a random image from the test set along with the model’s prediction for the same —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D