
Built a simple Artificial Neural Network using TensorFlow and Keras which classifies the organic compounds as either Musk or Non-Musk compounds
Aim
To develop a Deep Learning model that classifies the organic compounds as either Musk or Non-Musk compounds using python programming language and Deep learning libraries
Prerequisites
Before getting started, you should have a good understanding of:
- Python programming language
- Deep Learning Libraries(Tensorflow, Keras)
Dataset
Link to download the dataset:
https://datahub.io/machine-learning/musk
get the data
output:
--2021-07-06 11:17:20-- https://cainvas-static.s3.amazonaws.com/media/user_data/vomchaithany/musk.csv Resolving cainvas-static.s3.amazonaws.com (cainvas-static.s3.amazonaws.com)... 52.219.160.35 Connecting to cainvas-static.s3.amazonaws.com (cainvas-static.s3.amazonaws.com)|52.219.160.35|:443... connected. HTTP request sent, awaiting response... 304 Not Modified File ‘musk.csv’ not modified on server. Omitting download.
Import the required libraries
Load the data
output:
Preprocessing the Data
Split the data for training and test
output:
((4618, 166), (4618,))
Build, train, and save the model
output:
Epoch 1/15 145/145 [==============================] - 0s 3ms/step - loss: 0.4019 - accuracy: 0.8441 - val_loss: 0.2712 - val_accuracy: 0.9157 Epoch 2/15 145/145 [==============================] - 0s 2ms/step - loss: 0.2232 - accuracy: 0.9309 - val_loss: 0.1938 - val_accuracy: 0.9444 Epoch 3/15 145/145 [==============================] - 0s 2ms/step - loss: 0.1743 - accuracy: 0.9461 - val_loss: 0.1602 - val_accuracy: 0.9480 Epoch 4/15 145/145 [==============================] - 0s 2ms/step - loss: 0.1454 - accuracy: 0.9530 - val_loss: 0.1333 - val_accuracy: 0.9601 Epoch 5/15 145/145 [==============================] - 0s 2ms/step - loss: 0.1238 - accuracy: 0.9591 - val_loss: 0.1167 - val_accuracy: 0.9641 Epoch 6/15 145/145 [==============================] - 0s 2ms/step - loss: 0.1095 - accuracy: 0.9632 - val_loss: 0.1033 - val_accuracy: 0.9682 Epoch 7/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0946 - accuracy: 0.9693 - val_loss: 0.0946 - val_accuracy: 0.9646 Epoch 8/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0848 - accuracy: 0.9725 - val_loss: 0.0859 - val_accuracy: 0.9717 Epoch 9/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0758 - accuracy: 0.9766 - val_loss: 0.0798 - val_accuracy: 0.9732 Epoch 10/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0700 - accuracy: 0.9783 - val_loss: 0.0737 - val_accuracy: 0.9737 Epoch 11/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0611 - accuracy: 0.9831 - val_loss: 0.0670 - val_accuracy: 0.9783 Epoch 12/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0548 - accuracy: 0.9842 - val_loss: 0.0622 - val_accuracy: 0.9803 Epoch 13/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0505 - accuracy: 0.9857 - val_loss: 0.0612 - val_accuracy: 0.9798 Epoch 14/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0452 - accuracy: 0.9861 - val_loss: 0.0564 - val_accuracy: 0.9823 Epoch 15/15 145/145 [==============================] - 0s 2ms/step - loss: 0.0404 - accuracy: 0.9883 - val_loss: 0.0546 - val_accuracy: 0.9828
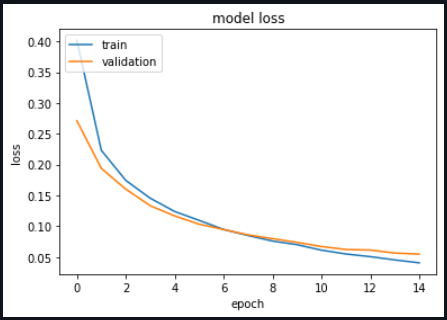
Graphs
loss vs validation loss
output:
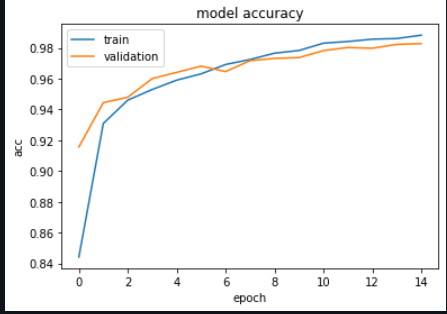
Accuracy vs validation accuracy
output:
Accuracy of our model
output:
62/62 [==============================] - 0s 1ms/step - loss: 0.0546 - accuracy: 0.9828 [0.0546199269592762, 0.9828282594680786]
Predictions
output:
array([[1.4935225e-03],
[6.3299501e-01],
[3.2852648e-03],
[7.9143688e-04],
[2.2959751e-04]], dtype=float32)
output:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
output:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0])
here we can see that the predicted values are the same as the actual values
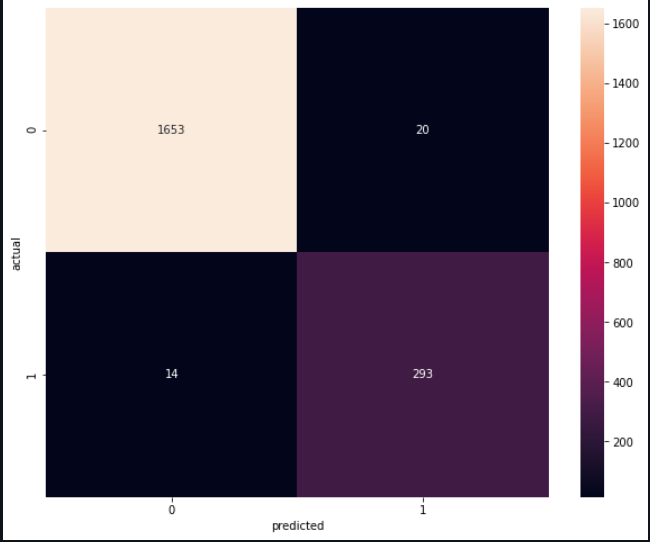
Classification report and Heat Map
output
precision recall f1-score support
0 0.99 0.99 0.99 1673
1 0.94 0.95 0.95 307
accuracy 0.98 1980 macro avg 0.96 0.97 0.97 1980 weighted avg 0.98 0.98 0.98 1980
Heat Map
output:
Link to access the notebook:
Conclusion:
We’ve trained our simple ANN using TensorFlow and Keras for classifying Musk /Non-Musk compounds and got an accuracy of 98%.
Notebook Link: Here
Credit: Om Chaithanya V
Also Read: Detecting Ships from Aerial Imagery using Deep Learning